

























目录
前言
学了一个晚上学了一点点皮毛可能还有很多地方有不足但是思想大概搞懂了(python的re库把我脑袋搞晕了QAQ)
这个大佬轻喷,有什么改进可以指出十分感谢
请求网页的源代码
定义头文件
许多网站为了防止有人恶意爬取,网站就会做反爬取
这个时候就要自己定义头文件,以便于可以正常显示源代码
比如csdn不定义User-Agent返回的源代码就为空
按f12打开控制台,打开网络(network)刷新网页,随便点击一个链接在请求的文件里有
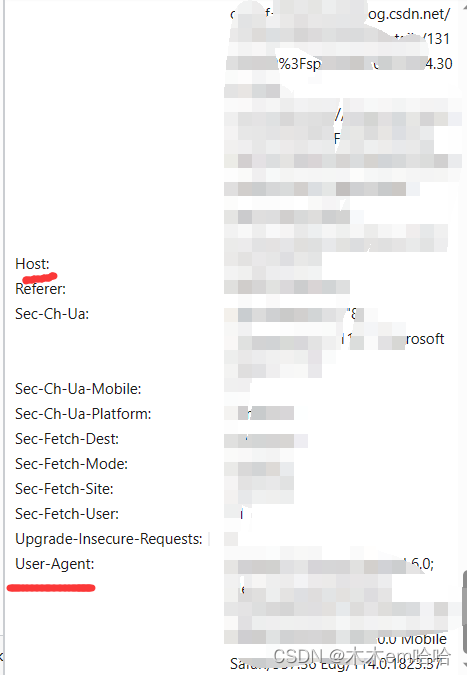
一般用到的就是User-Agent,host,cookie,Accept和connection
这边我就定义一个头文件变量
headers_dict={
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Mobile Safari/537.36 Edg/114.0.1823.37'
}爬取源代码
然后开始爬取网页源代码
并且把源代码存起来
response = requests.get('https://blog.csdn.net/mumuemhaha/article/details/131031052?spm=1001.2014.3001.5501',headers=headers_dict)
html_1=response.text开始选取所需要的部分
用PyQuery选择相应的区块(分支可看可不看)
PyQuery可以把源代码中的<div class=" a_1">...</div>和<ul id = "b_1 "></ul>,<c_1>和</c_1>的部分筛选出来
可以用
doc = pq(html)
print(doc('.a_1 #b_1').find("c_1"))
其中a_1代表的就是.(英文句号)+div class=" "空的值
b_1代表的就是ul id = " "空的值
c_1代表得到就是两个标签名称上面就"<li>"
优点
是语法相对比较简单
可以快速选择所需要的区域
缺点
只凭这个无法定位标签栏里面的元素,尤其是图片链接
开始定位链接的位置(使用正则表达式)
这时候就要用re库来选择连接内容了
这里选择一个简单正则表达式的方便理解
ex = '.*? src="(.*?)" .*?'这里.*?代表的随机的值
而加个()就是要选择的值
这里的意思就是所有src="x_1"中x_1的值
然后调用re.findall()进行选择并且打印(或者存入txt文件也行)
ex = 'src="(.*?)"'
imglist = re.findall(ex, html_2)
print(imglist)
#['https://csdnimg.cn/release/blogv2/dist/mobile/img/iconLeftArrow.png', 'https://profile-avatar.csdnimg.cn/7611198b454e45eab7a77034fbc1c227_mumuemhaha.jpg!1']出现的奇怪的问题
Traceback (most recent call last):
File "D:\python\os\main_request.py", line 22, in <module>
imglist = re.findall(ex, html_1)
File "C:\Users\mumuemhaha\AppData\Local\Programs\Python\Python39\lib\re.py", line 241, in findall
return _compile(pattern, flags).findall(string)
TypeError: expected string or bytes-like object这里就是因为PyQuery选取的区域格式不是string的
request获取的源代码时“<class 'str'>”而PyQuery选取出来的区域是<class 'pyquery.pyquery.PyQuery'>不过问题不大
强制格式转换就行
html_1=str(html_1)所有源代码(包括我验证PyQuery是不是string的语句也在上面)
import requests
import re
from pyquery import PyQuery as pq
headers_dict={
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Mobile Safari/537.36 Edg/114.0.1823.37'
}
response = requests.get('https://blog.csdn.net/mumuemhaha/article/details/131031052?spm=1001.2014.3001.5501',headers=headers_dict)
html_1=response.text
html_2=response.text
doc=pq(html_1)
html_1=doc('.aside-header-fixed .aside-left')
html_1=str(html_1)
print(type(html_2))
print(type(html_1))
ex = 'src="(.*?)"'
imglist = re.findall(ex, html_1)
print(imglist)
# print(html_1)
如果这篇文章对你有帮助,欢迎分享给更多人!
部分信息可能已经过时