目录
下一章内容
 https://blog.csdn.net/mumuemhaha/article/details/133554220?spm=1001.2014.3001.5501 ;
https://blog.csdn.net/mumuemhaha/article/details/133554220?spm=1001.2014.3001.5501 ;为什么要使用多线程
在我们实际处理问题中可能会遇到一些需要等待或者是需要时间去等待放回的问题
比如像网络爬虫的数据包返回,亦或者程序对cpu的使用率不高,导致时间和性能的浪费
同时多线程可以实现异步编程,将一些耗时的操作放在后台线程执行,使得主线程能够继续响应用户的其他操作,提高程序的并发性。
综上所述,多线程编程对于我们大部分编程语言的学习都是必须要学习的。
例子
在这里我先放一个源代码在这,这是我们用原先的方法进行顺序执行
代码
|
|
其中time.h库中的clock_t以及clock()是是用来统计程序运行的时间的 this_thread::sleep_for(chrono::seconds(i))这个函数是个休眠函数,为等待i秒,用来模拟程序运行的时间
结果
程序运行的结果
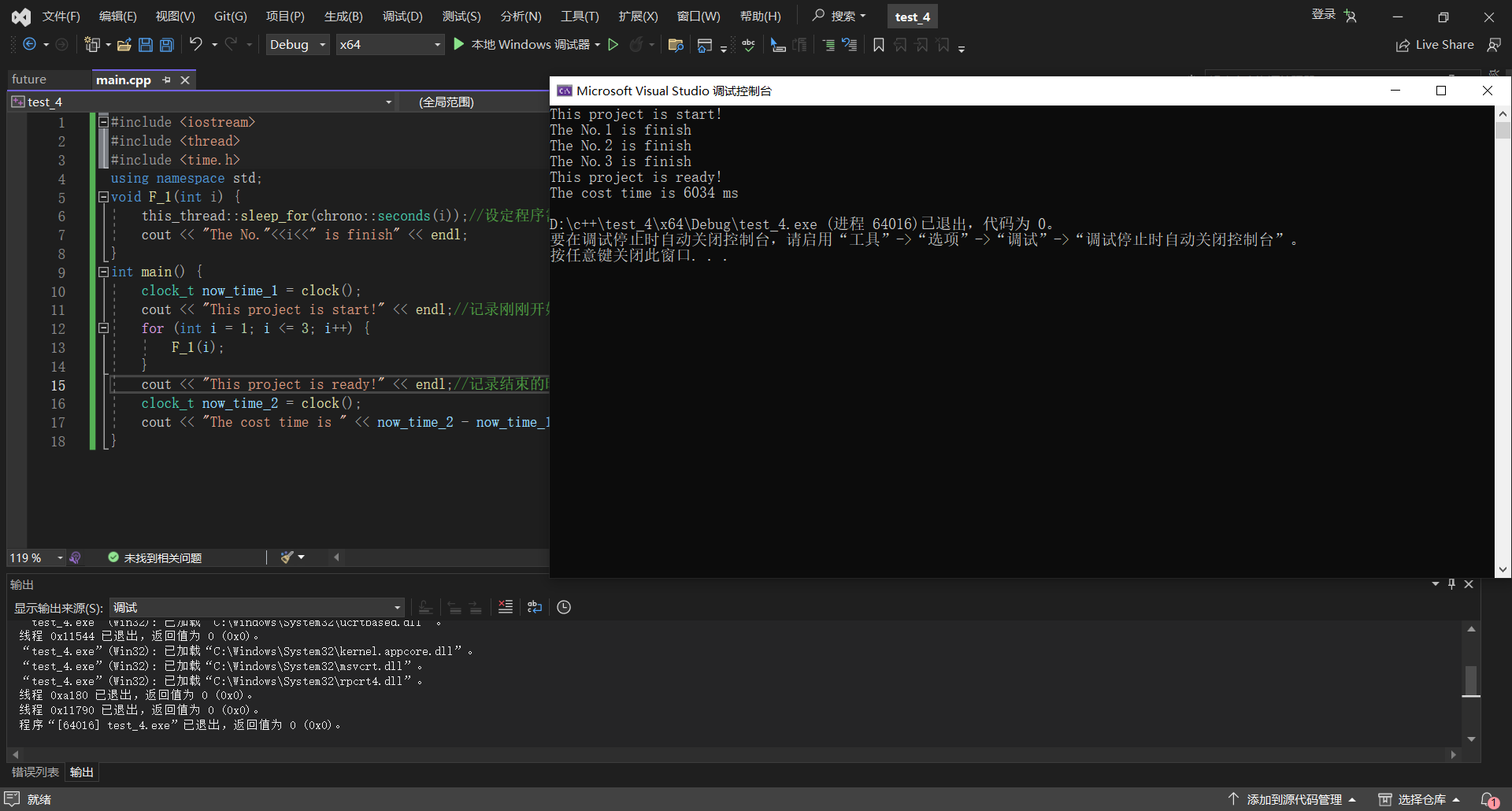
如图程序一共运行了6000ms的时间
首先要先学的库——thread库
thread的简介
C++ 作为一种强大的编程语言,为多线程编程提供了丰富而灵活的支持。C++ 的标准库提供了
<thread></thread>头文件,其中包含了用于创建、启动和管理线程的类和函数。通过使用这些多线程库和功能,开发人员可以轻松地引入并发性到自己的应用程序中,实现多线程的并行处理。
thread的具体使用方法
基本变量的定义
thread函数中定义线程的语法规如下
|
|
注意(小重点)
其中如果原函数传递的参数为左值(也就是int &a)那么传递的参数应该把原来的a,b…改为ref(a),ref(b)或者cref(a),cref(b)…
原因是thread为右值传递,函数讲道理应该不能用引用也就是右值。
至于啥是左值啥是右值?
简单来说就是左值是内存上有空间或者是有地址的,而右值就是内存上没空间或者是只有临时地址的,举个例子
|
|
那为什么ref以及cref可以呢?
- ref可以包装按引用传递的值为右值。
- cref可以包装按
const引用传递的值为右值。
他们都是经过从左值转为右值的转化的(但是实际还是左值)
join函数的解读(重点)
join函数就是等待副线程完毕才可以进行join()函数下面的部分
join函数看起来是加入,有一些人(包括我)把它看成加入线程池,其实我觉得把它换成wait其实更好一点……,因为join简单来说就是堵塞主线程,一直到函数运行完毕才可以进行下一步
简单来说就是这样一个图
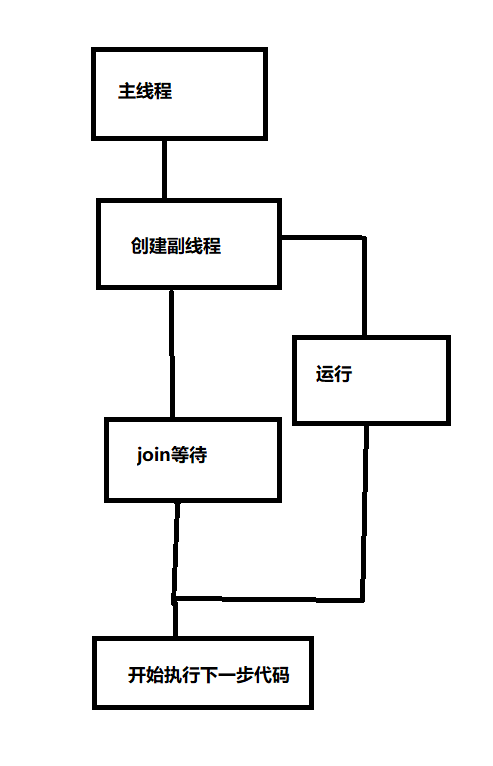
这样看就是很完整了,不然如果是运行join()才加入的话,那样运行时间和上面代码没什么区别……
detach函数的解读
detach函数就是比较简单的
笼统的来说:就是把它和主线程分离,两人谁也不等谁(但是其实主线程结束后,副线程由于守护线程的结束也会停止)
注意
如果你不使用或者是多次使用join或者detach两个中的一个函数,程序都会报错
关于vector和thread是联合使用
代码
|
|
如上使用就可以了
join函数就可以这样使用
|
|
例子中代码的改良
那么例子中提到的代码就可以进行修改了
代码
|
|
代码中创建的一个容器进行装载三个线程
然后创建过程中已经一起执行了
运行结果
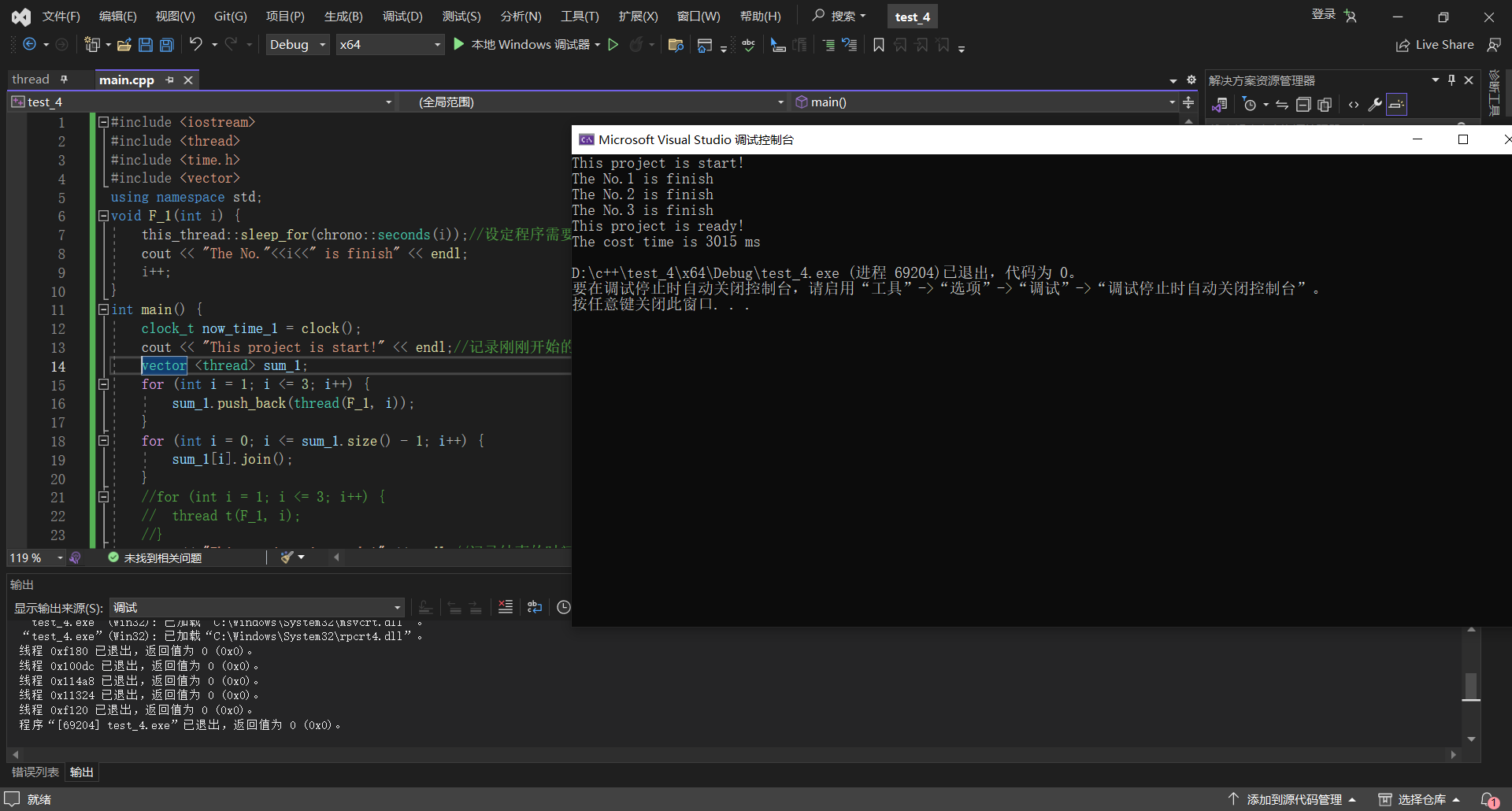
如图,为3015ms,节约的时间十分的可观
总结
在编程中多线程操作一般可以节约可观的时间,并且可以对自己的程序进行一些优化
尽管现在只学了thread库,但是不要担心
接下来我会按照我的学习路线依次把我的学习笔记给写下来
是不是少了什么?
哦,对了
