目录
前因
首先的尝试
解决办法
导入包
定义一个json配置文件
打开浏览器执行操作
注意
提取源代码并且进行筛选链接
执行结果
前因
由于自己要把csdn的博客同步到hugo中,把博客转为md格式已经搞好了,但是由于csdn的图片具有防盗链,所以打算把所有的图片爬取下来,然后保存在本地
刚好本人略懂一些python,所以自己先写了一个脚本用来爬取各个博客的链接,如果不想听我多bb的直接去我的github看源码
GitHub - mumuhaha487/Get_csdn Contribute to mumuhaha487/Get_csdn development by creating an account on GitHub. https://github.com/mumuhaha487/Get_csdn ;
https://github.com/mumuhaha487/Get_csdn ;
首先的尝试
首先的尝试就是利用简单好用的request包进行爬取。
但是由于csdn的博客是不显示全部,滑动底部时更新一部分
request包可能做不了这么复杂的工作QAQ
好像https://blog.csdn.net/你的名字/article/list/链接可以用request包进行爬取
解决办法
那么恰好我有学过一点点的selenium包,所以搞了一个自动化的形式通过模拟鼠标滑动到文章的底部来获取到所有的文章链接
导入包
各个包都有解释用途
1
2
3
4
5
6
|
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains #用于自动化框架执行动作
import time #延时操作,方便网站加载完全
import json #用于读取配置信息
import re #从源代码中提取文章的链接
|
定义一个json配置文件
定义一个json配置文件方便管理
现在文件只有用户名称,后续可加配置
1
2
3
|
{
"blog_id": "mumuemhaha"
}
|
读取用户名称,并且将其拼接成csdn个人博客链接
1
2
3
4
5
|
with open("./config.json",'r') as file_1:
data_1=json.load(file_1)
blog_id=data_1["blog_id"]
url_1=f"https://blog.csdn.net/{blog_id}?type=blog"
|
打开浏览器执行操作
注意
这里由于不知道要下滑多少次,所以可以设定一个很大的数字然后每滑动十次判断源代码是否更新,然后源代码没有变化则跳出循环即可(
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
driver = webdriver.Chrome()
driver.get(url_1)
for i in range(10000):
time.sleep(0.5)
actions = ActionChains(driver)
actions.send_keys(Keys.PAGE_DOWN) # 可以多次发送 PAGE_DOWN 来实现滚动的距离
actions.perform()
if i % 10 == 0: # 每滑动 10 次进行判断
prev_page_source = driver.page_source # 获取前一次滑动后的页面源码
time.sleep(2) # 等待页面加载
current_page_source = driver.page_source # 获取当前页面源码
if prev_page_source == current_page_source:
print("网站滑倒底了,跳出循环...")
break
|
提取源代码并且进行筛选链接
1
2
|
req_1=driver.page_source
re_1='
|
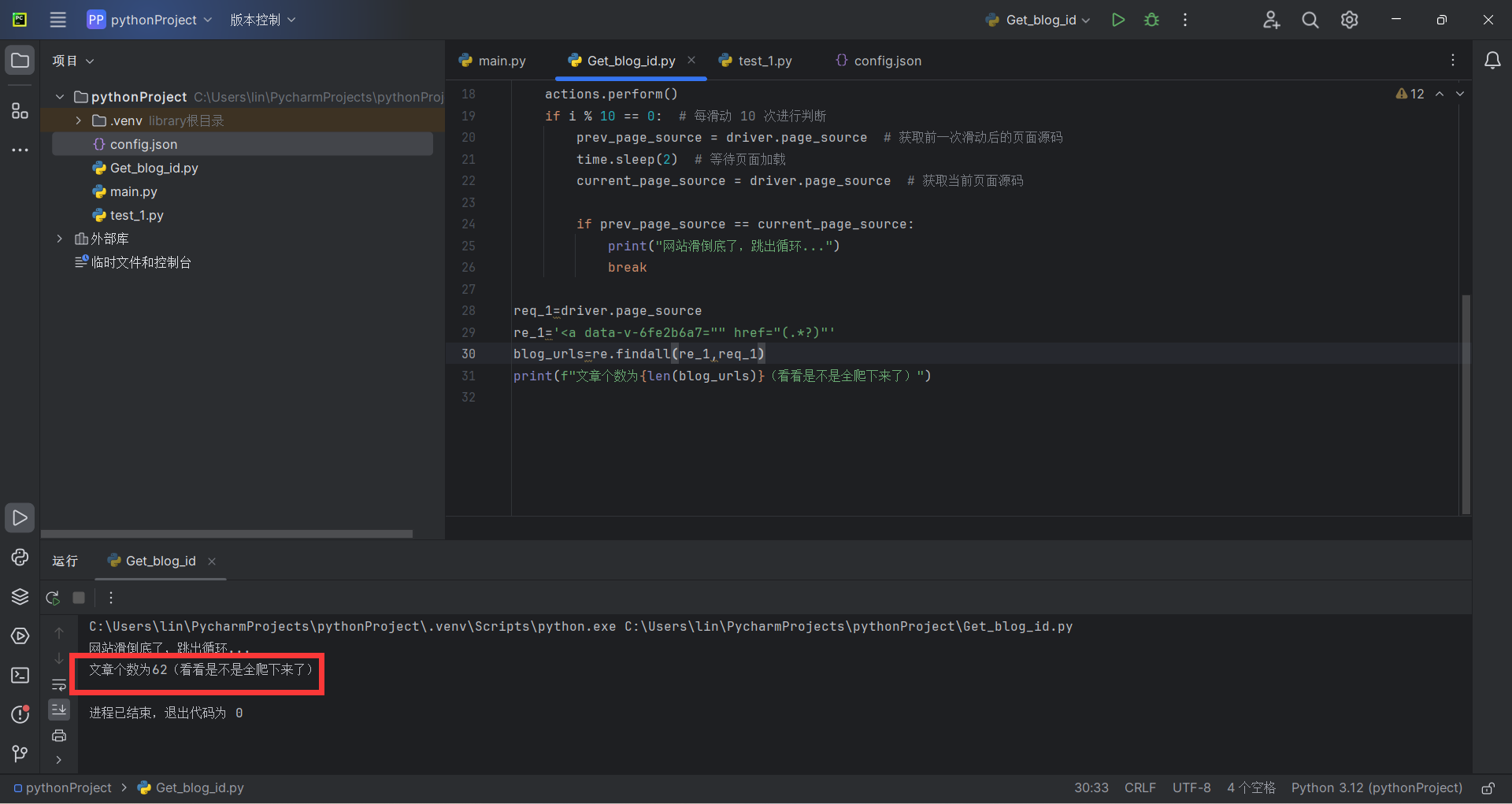
执行结果
我加了一个打印链接个数的代码来判断是否全部爬取下来了
1
|
print(f"文章个数为{len(blog_urls)}(看看是不是全爬下来了)")
|
全部代码为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains #用于自动化框架执行动作
import time #延时操作,方便网站加载完全
import json #用于读取配置信息
import re #从源代码中提取文章的链接
with open("./config.json",'r') as file_1:
data_1=json.load(file_1)
blog_id=data_1["blog_id"]
url_1=f"https://blog.csdn.net/{blog_id}?type=blog"
driver = webdriver.Chrome()
driver.get(url_1)
for i in range(10000):
time.sleep(0.5)
actions = ActionChains(driver)
actions.send_keys(Keys.PAGE_DOWN) # 可以多次发送 PAGE_DOWN 来实现滚动的距离
actions.perform()
if i % 10 == 0: # 每滑动 10 次进行判断
prev_page_source = driver.page_source # 获取前一次滑动后的页面源码
time.sleep(2) # 等待页面加载
current_page_source = driver.page_source # 获取当前页面源码
if prev_page_source == current_page_source:
print("网站滑倒底了,跳出循环...")
break
req_1=driver.page_source
re_1='
|